MB XSS Challenge

Some time ago, Michał Bentkowski published an XSS challenge on his twitter. I accepted the challenge, and here is my story.
Introduction
When I entered the website, I got a set of rules:
- Please enter some HTML. It gets sanitized and inserted to a <div>.
- The task is: execute alert(1).
- The solution must work on current version of at least one major browser (Chrome/Edge, Firefox, Safari).
- The challenge is based on code seen in the wild.
I also got a textarea. It suggested that the problem was quite popular. Isn’t that exciting?
After typing a few things into the input, nothing really happened. Let’s inspect the code.
function process() {
const input = getInput();
history.replaceState(null, null, ‘?xss=‘+encodeURIComponent(input));
const div = document.createElement(‘div’);
div.innerHTML = sanitize(input);
// document.body.appendChild(div)
}
We have a getInput function, which simply fetches the value from the textarea. Then we create a new div. After that, we use a sanitize function to sanitize the value of textarea, and we assign it to the div through innerHTML. Then we have this commented part of the code, which adds it to the DOM.
Let’s keep this in mind and look into the sanitize function.
function sanitize(input) {
const TAG_REGEX = /<\/?(\w*)([^>]*)>/gmi;
const COMMENT_REGEX = /<!--.*?-->/gmi;
const END_TAG_REGEX = /^<\//;
// Taken from XSS Cheat Sheet by Portswigger
const FORBIDDEN_ATTRS = ["onactivate","onafterprint","onanimationcancel","onanimationend","onanimationiteration",
"onanimationstart","onauxclick","onbeforeactivate","onbeforecopy","onbeforecut","onbeforedeactivate",
"onbeforepaste","onbeforeprint","onbeforeunload","onbegin","onblur","onbounce","oncanplay","oncanplaythrough",
"onchange","onclick","oncontextmenu","oncopy","oncut","ondblclick","ondeactivate","ondrag","ondragend",
"ondragenter","ondragleave","ondragover","ondragstart","ondrop","onend","onended","onerror","onfinish",
"onfocus","onfocusin","onfocusout","onhashchange","oninput","oninvalid","onkeydown","onkeypress","onkeyup",
"onload","onloadeddata","onloadedmetadata","onloadend","onloadstart","onmessage","onmousedown","onmouseenter",
"onmouseleave","onmousemove","onmouseout","onmouseover","onmouseup","onpageshow","onpaste","onpause","onplay",
"onplaying","onpointerover","onpointerdown","onpointerenter","onpointerleave","onpointermove","onpointerout",
"onpointerup","onpointerrawupdate","onpopstate","onreadystatechange","onrepeat","onreset","onresize",
"onscroll","onsearch","onseeked","onseeking","onselect","onstart","onsubmit","ontimeupdate","ontoggle",
"ontouchstart","ontouchend","ontouchmove","ontransitioncancel","ontransitionend","ontransitionrun",
"onunhandledrejection","onunload","onvolumechange","onwaiting","onwheel"];
const FORBIDDEN_TAGS = ["script", "style", "noscript", "template", "svg", "math"];
let sanitized = input;
sanitized = sanitized.replace(COMMENT_REGEX, '');
sanitized = sanitized.replace(TAG_REGEX, (wholeTag, tagName, attributes) => {
tagName = tagName.toLowerCase();
if (FORBIDDEN_TAGS.includes(tagName)) return '';
if (END_TAG_REGEX.test(wholeTag)) {
return `</${tagName}>`;
}
for (let attr of FORBIDDEN_ATTRS) {
attributes = attributes.replace(new RegExp(attr + '\\s*=', 'gi'), '_ROBUST_XSS_PROTECTION_=');
}
return `<${tagName}${attributes}>`
});
return sanitized;
}
This function is quite long. Let’s analyze it step by step. First we have three regexps for tags, comments, and the end tags:
const TAG_REGEX = /<\/?(\w*)([^>]*)>/gmi;
const COMMENT_REGEX = /<!--.*?-->/gmi;
const END_TAG_REGEX = /^<\//;
Then we have FORBIDDEN_ATTRS and FORBIDDEN_TAGS. FORBIDDEN_ATTRS is a long set of all (or maybe not all?) tokens. Even the comment says that this is copied from the Portswigger. I checked a few ones, such as onbeforeprint. I was wondering if there were some missing ones, but just finding one of them wouldn’t be a very exciting task.
The much smaller list was in the FORBIDDEN_TAGS—the list of tags that are not allowed. Those tags will be removed. I momentarily noticed that object is not on the list, so I created a simple XSS using the object tag:
<object data=“data:text/html;base64,PHNjcmlwdD5hbGVydCgxKTs8L3NjcmlwdD4K”></object>
I tried it … and nothing happened. Hmm. I recalled the commented line. I uncommented it and checked one more time, and it did work this time.
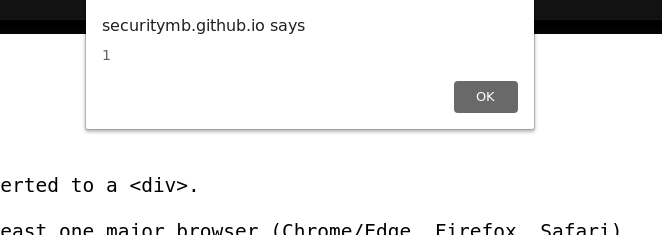
Are those commented out lines a bug in the task? I decided to reach out to the author, and he said that those lines were commented intentionally. Interesting.
Okay, let’s play this game!
The code removes the HTML comments next. After that is the main sanitization function. We are looking for each tag using TAG_REGEX. There is a check for any forbidden tags, and if any are found, they are removed. Then we check if this is a closing tag. In this case, the tag is returned, but the attributes from it are removed, as well. The last part goes over the attributes, and all of the attributes from the FORBIDEN_ATTRS are removed with the _ROBUST_XSS_PROTECTION_. After sanitizing the attributes, the tag is returned with new attributes. Finally, the new text is returned.
Images Are the First Key
What can we do with the part of our content that is never really rendered? If the text was added to the DOM, we could use the object to exploit it, but it isn’t.
While I was playing with the input, I noticed that there was different behavior between object and audio or img tags. For audio or img, even if the object is not rendered in the DOM, the browser sends a request to fetch an image file at the moment when the HTML is assigned to the innerHTM.

This browser behavior is done to minimize the time that users need to wait for the images. The browser fetches them as soon as it knows that they may be used. That’s cool! Maybe we can use it.
What is also interesting is that when the file is prefetched, some of the handlers are executed even if the object is not part of the DOM. For example, if the img tag has an onerror handle, it will be executed immediately after fetch is filed.
I spent the next couple minutes looking into the different attributes specified for the image/audio/video file to figure out if there was some attribute I could use, but nothing really worked, or it was already blacklisted.
Fooling RegExps
Finally, I figured out that to exploit this, I somehow have to trick the regexp. Let’s look one more time into the TAG_REGEX, this time with the regexper.
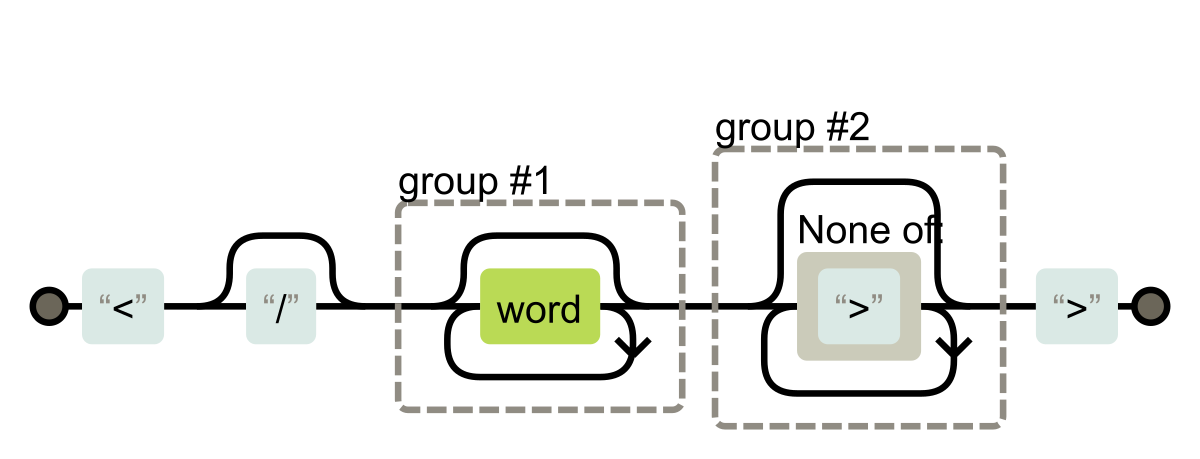
The TAG_REGEX matches the tag till the > sign. Can I somehow add the > sign in our tag without really ending it? What if the > character was one of the attributes?
<img alt=“>“ src=“a.png” onerror=alert(1)>
Bingo! Sanitizer thinks that the tag is only <img alt=“>, and doesn’t have any forbidden tags, but actually, it’s much longer. Because we are using the img tag, the browser is automatically fetching the a.png file because such a file doesn’t exist when the onerror is triggered.
Summary
I solved an XSS challenge, and I went through some weird browser behaviors to finally exploit the target. Who would have thought that XSS bugs could be so interesting.